
Cybersecurity Datasets:
13. DNS Malicious Traffic (CIC-Bell-DNS2021)
A collaborative project with Bell Canada (BC) Cyber Threat Intelligence (CTI)
Malicious domains are one of the major threats that have jeopardized the viability of the Internet over the years. Threat actors usually abuse the Domain Name System (DNS) to lure users to be victims of malicious domains hosting drive-by-download malware, botnets, phishing websites, or spam messages. Each year, many large corporations are impacted by these threats, resulting in huge financial losses in a single attack. Thus, detecting and classifying a malicious domain in a timely manner is essential.
Previously, filtering the domains against blacklists was the only way to detect malicious domains, however, this approach was unable to detect newly generated domains. Recently, Machine Learning (ML) techniques have helped to enhance the detection capability of domain vetting systems. A solid feature engineering mechanism plays a pivotal role in boosting the performance of any ML model. Therefore, we have extracted effective and practical features from DNS traffic categorizing them into three groups of lexical-based, DNS statistical-based, and third party-based features. Third party features are biographical information about a specific domain extracted from third party APIs. The benign to malicious domain ratio is also critical to simulate the real-world scheme where approximately 99% of the traffic is devoted to benign.
In this research work, we generate and release a large DNS features dataset of 400,000 benign and 13,011 malicious samples processed from a million benign and 51,453 known-malicious domains from publicly available datasets. The malicious samples span between three categories of spam, phishing, and malware. Our dataset, namely CIC-Bell-DNS2021 replicates the real-world scenarios with frequent benign traffic and diverse malicious domain types.
We train and validate a classification model that, unlike previous works that focus on binary detection, detects the type of the attack, i.e., spam, phishing, and malware. Classification performance of various ML models on our generated dataset proves the effectiveness of our model, with the highest, is k-Nearest Neighbors (k-NN) achieving 94.8% and 99.4% F1-Score for balanced data ratio (60/40%) and imbalanced data ratio (97/3%), respectively. Finally, we have gone through feature evaluation using information gain analysis to get the merits of each feature in each category, proving the third party features as the most influential one among the top 13 features.
We provide a methodology for feature engineering of packet captures. We develop 32 clearly defined discriminative features including lexical-based, DNS statistical-based, and third party-based (biographical) features.
First, the captured DNS PCAP file is read and all the domains in the answer section of type A, AAAA, and CNAME query responses are retained. The field “rrname” keeps the domain name. Meanwhile, the statistical features are extracted from the structure of the DNS message in a specific packet window. Then, for each captured domain, we extract the lexical and third party features.
DNS statistical features are statistical information computed from the answer section of the DNS responses. The statistical functions are the average of Time-to-Live (TTL), the variance of TTL, distinct number of TTL, domain, IP, ASN, and country in each DNS packet. The features are computed within a sliding window of length τ with a stride of s.
Lexical features help detect malicious domain names since attackers apply different typosquatting and obfuscation methods to mimic the real domain names. In this research, we have extracted twelve features from each domain elaborated as follows:
Subdomain: Most malicious domains have few subdomains to mimic the real domain. For instance, to mimic www.facebook.com, the malicious domain could be in the format of www.facebook.f.com. In this case, the Top-Level Domain (TLD) is f and not facebook. However, people without enough background knowledge may be deceived.
Top-Level Domain (TLD): Based on the previous studies, most malicious domains are with specific TLDs for a long duration of time, such as .com, .pw, to name a few. The possibility of a URL being malicious is higher when its TLD historically has been used for phishing URLs.
Second-Level Domain (SLD): SLD is the most critical part of a domain. Extracting features from SLD can help us get more information regarding the organization that registered the domain name. For example, in www.facebook.com, facebook is the SLD.
Length: The length of the domain consists of SLD and subdomains. Because phishing URLs or malicious domains are lengthy based on the previously discovered malicious URLs, considering the length feature is necessary.
Numeric percentage: This feature indicates the percentage of numerical characters to the length of the domain.
Character distribution: This feature computes the distribution of each letter in the domain.
Entropy: This feature is based on the letter distribution and Shannon's entropy formula.
N-gram: This feature extracts the uni-gram, bi-gram, and tri-gram of the domain at the character level.
Longest meaningful word: This feature will find the longest word in the domain. To this end, we used a dictionary of words with their frequencies. Then, we apply dynamic programming to infer the location of spaces in the domain.
Distance from bad words: There is a blacklist of all suspicious and harmful words. After tokenizing the domain to meaningful words, we get the average of the Levenshtein distance of the domain's words from the blacklist.
Typosquatting method: There are generally five Typosquatting types including misspellings, singular versions, plural versions, hyphenations, and common domain extensions. We retrieve the list of 500 top domains from Alexa [15], which are all benign and known domain names. Then we extract the best matches from the dictionary to our domains, and each match has a score. Based on a threshold on the score, we mark the domain as a typo or not. For example, if our domain would be go0gle.com, it will return google.com as the best match with an 85% score; hence, we mark it as a typo.
Obfuscation method: To the best of our study, we considered nine different ways by which each domain can be obfuscated. If any of the following methods have been applied by the attacker, we mark the domain name as obfuscated:
1.existing @ in URL,
2.IP obfuscation Decimal 8 bits,
3.IP obfuscation Decimal 32 bits,
4.IP obfuscation Octal 8 bits,
5.IP obfuscation Octal 32 bits,
6.IP obfuscation Hexadecimal 8 bits,
7.IP obfuscation Hexadecimal 32 bits,
8.Detecting IDN: suspicious domain name may be encoded with Unicode or international domain names encoded with Punycode, and
9.Shortened URLs: to confirm if it has been shortened or not, we send a request to see if it gets redirected to the real URL or not.
The third party features are extracted from two third party sources, i.e., Whois and Alexa rank and they contain the biographical properties of a domain. Table 1 depicts the final 32 DNS features.
Table 1: List of DNS-based features
Feature - Feature name - Description
Lexical:
F1 - Subdomain - Has sub-domain or not
F2- TLD- Top-level domain
F3- SLD- Second-level domain
F4- Len- Length of domain and subdomain
F5- Numeric percentage -Counts the number of digits in domain and subdomain
F6- Character distribution- Counts the number of each letter in the domain
F7- Entropy- Entropy of letter distribution
F8- 1-gram- 1-gram of the domain in letter level
F9- 2-gram- 2-gram of the domain in letter level
F10- 3-gram- 3-gram of the domain in letter level
F11- Longest word- Longest meaningful word in SLD
F12- Distance from bad words- Computes average distance from bad words
F13- Typos- Typosquatting
F14- Obfuscation- Max value for URL obfuscation
DNS statistical:
F15- Unique country- The number of distinct country names in window τ
F16- Unique ASN- The number of distinct ASN values in window τ
F17- Unique TTL- The number of distinct TTL values in window τ
F18- Unique IP -The number of distinct IP values in window τ
F19- Unique domain- The number of distinct domain values in window τ
F20- TTL mean -The average of TTL in window τ
F21- TTL variance- The variance of TTL in window τ
Third party:
F22- Domain name- Name of the domain
F23- Registrar- Registrar of the domain
F24- Registrant name- The name the domain has been registered
F25- Creation date time- The date and time the domain created
F26- Emails- The emails associated to a domain
F27- Domain age- The age of a domain
F28- Organization- What organization it is linked to
F29- State -The state the main branch is
F30- Country- The country the main branch is
F31- Name server count- The total number of name servers linked to the domain
F32- Alexa rank- The rank of the domain by Alexa
Figure 1 shows four main stages of our proposed model we followed to detect malicious domains and classify them into one of the categories of malware, spam, phishing, and benign.
Figure 1: Stages of the proposed model
 The first stage, which is gathering domains, focuses on collecting a large corpus of benign and malicious domains from Majestic Million, OpenPhish, PhishTank, DNS-BH, malwaredomainlist, and jwspamspy spanning between four different categories of benign, phishing, malware, and spam.
The first stage, which is gathering domains, focuses on collecting a large corpus of benign and malicious domains from Majestic Million, OpenPhish, PhishTank, DNS-BH, malwaredomainlist, and jwspamspy spanning between four different categories of benign, phishing, malware, and spam.
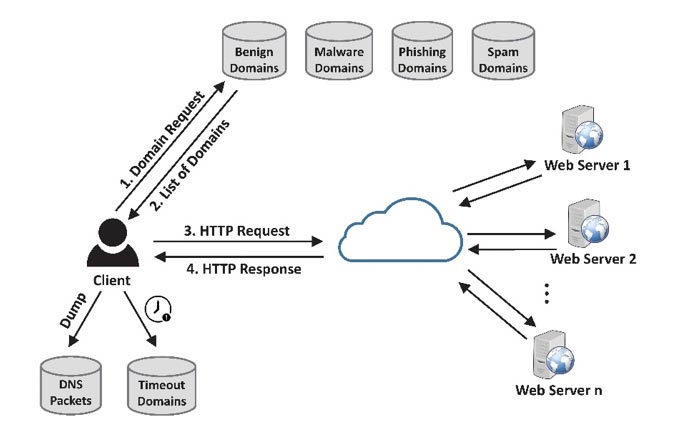
In the second stage, dataset generation, we send HTTP requests using a Python script to the collected domains and the related network packets are captured using Wireshark. The detailed steps are illustrated in Figure 2. First, all the domains are retrieved from the client's local database (steps 1 and 2). Then, an HTTP request is sent to each domain's web server through the Internet and the OK (200) response is received back in steps 3 and 4. Meanwhile, the DNS packets are dumped and the domains with a timed-out request are just ignored. To avoid long waiting times, we set the timeout parameter to two seconds.
Figure 2: DNS packet capture
 After capturing the DNS packets, we pre-process the captured packets by keeping only type A, AAAA, and CNAME query responses (only type A and AAAA contain an IP address). We discard the queries and type SOA query responses. We then apply our DNS feature extractor to extract 32 final DNS features from the captured packets. After that, all the features are post-processed.
After capturing the DNS packets, we pre-process the captured packets by keeping only type A, AAAA, and CNAME query responses (only type A and AAAA contain an IP address). We discard the queries and type SOA query responses. We then apply our DNS feature extractor to extract 32 final DNS features from the captured packets. After that, all the features are post-processed.
The categorical features namely, sld, emails, domain name, country, registrar, state, registrant name, longest word, organization, tld are transformed and represented as continuous values. Average of n-gram frequencies, char distribution, typos, distance from bad words were computed. Also, creation date time and domain age are converted to seconds and years, respectively. The rest of the numerical features remain unchanged. Besides, we calculate the maximum value of the nine obfuscation methods and merge them all into one feature of obfuscation. Finally, we create a CSV file of all the post-processed features values.
The third stage trains the ML model, and the fourth stage validates and evaluates the model using fold cross-validation.
One of the contributions of this research is to generate a large DNS features dataset based on the malicious and benign domains. As explained earlier, we sent HTTP requests to the gathered domains and the associated packets were captured. Then the captured packets were pre-processed, and the proposed features were extracted from the packets using our developed DNS-based feature extractor. Finally, the features were post-processed to create the final dataset. We make our dataset (CIC-Bell-DNS2021) publicly available for further research improvements in this area.
We managed to collect more than one million domains from various sources falling under four different categories of malware, spam, phishing, and benign domains. All the domains have been collected between May 2019 to June 2019 and later updated with domains from December 2020 for further validation. Each domain category is briefly explained as follows:
Malware domains:
Malware category refers to the domains that have been previously identified to generate any general type of malware including drive-by download, DGA-based botnets, Distributed Denial of Service (DDoS) attacks, and spyware. The malware domains were collected from DNS-BH and malwaredomainlist.
Spam domains:
Spammers employ different ways to find valid email addresses for sending bulk emails. Dictionary harvest attack is one of the common ways to seek a valid email address by randomly sending mail to widely used mailbox names for a domain, such as info@example.com, admin@example.com, and support@example.com. We have obtained Spam domains from jwspamspy [21] which works as an e-mail spam filter for Microsoft Windows.
Phishing domains:
Phishing domains imitate the looks of legitimate websites and leverage social engineering techniques to trick users into clicking the malicious link. Upon clicking the fake link through email or SMS, the user is directed to an imposter website asking for the user's login credentials and private information. In our dataset, the phishing domains were collected from OpenPhish and PhishTank which are collaborative phishing verification websites where the users submit the phishing data, and the community users vote for it.
Benign domains:
All the domains that are not in the above categories are deemed to be benign. We gathered all benign domains from Majestic Million.
Table 2 shows the breakdown of the dataset in terms of the number of collected domains (#original domain) in each category of malware, spam, phishing, and benign. After sending HTTP requests to each domain, some of the domains do not respond, e.g., C&C servers that are not alive anymore. The remaining domains that respond OK (200) are logged and, associated DNS packets are dumped. In Table 2, the domains and packets that have been successfully processed are identified with columns “#domains processed” and “#packets processed”, respectively.
Table 2: Statistics of the domains dataset
Category -Original domains -Domains processed -Packets processed
Malware -26,895 -9,432 -182,266
Spam- 8,254 -1,976 -61,046
Phishing -16,307 -12,586- 95,492
Benign- 988,667- 500,000 -6,907,719
In the analysis step, we applied a set of ML algorithms on two subdivisions of our dataset, namely balanced and imbalanced. First, we balanced the number of spam, malware, and phishing datasets each having 4,337 samples to generate a total of 13,011 malicious samples. For the benign samples, we created two categories of 20,000 and 400,000 samples for the balanced and imbalanced subdivisions of our dataset, respectively. Thus, we end up with a data ratio of 60/40% (benign/malicious) for a balanced dataset and 97/3% (benign/malicious) for an imbalanced dataset.
You may redistribute, republish, and mirror the CIC-Bell-DNS2021 dataset in any form. However, any use or redistribution of the data must include a citation to the CIC-Bell-DNS2021 dataset and the following paper:
- Samaneh Mahdavifar, Nasim Maleki, Arash Habibi Lashkari, Matt Broda, Amir H. Razavi, “Classifying Malicious Domains using DNS Traffic Analysis”, The 19th IEEE International Conference on Dependable, Autonomic, and Secure Computing (DASC), Oct. 25-28, 2021, Calgary, Canada
You can download this dataset from here.
Previously, filtering the domains against blacklists was the only way to detect malicious domains, however, this approach was unable to detect newly generated domains. Recently, Machine Learning (ML) techniques have helped to enhance the detection capability of domain vetting systems. A solid feature engineering mechanism plays a pivotal role in boosting the performance of any ML model. Therefore, we have extracted effective and practical features from DNS traffic categorizing them into three groups of lexical-based, DNS statistical-based, and third party-based features. Third party features are biographical information about a specific domain extracted from third party APIs. The benign to malicious domain ratio is also critical to simulate the real-world scheme where approximately 99% of the traffic is devoted to benign.
In this research work, we generate and release a large DNS features dataset of 400,000 benign and 13,011 malicious samples processed from a million benign and 51,453 known-malicious domains from publicly available datasets. The malicious samples span between three categories of spam, phishing, and malware. Our dataset, namely CIC-Bell-DNS2021 replicates the real-world scenarios with frequent benign traffic and diverse malicious domain types.
We train and validate a classification model that, unlike previous works that focus on binary detection, detects the type of the attack, i.e., spam, phishing, and malware. Classification performance of various ML models on our generated dataset proves the effectiveness of our model, with the highest, is k-Nearest Neighbors (k-NN) achieving 94.8% and 99.4% F1-Score for balanced data ratio (60/40%) and imbalanced data ratio (97/3%), respectively. Finally, we have gone through feature evaluation using information gain analysis to get the merits of each feature in each category, proving the third party features as the most influential one among the top 13 features.
Proposed features
First, the captured DNS PCAP file is read and all the domains in the answer section of type A, AAAA, and CNAME query responses are retained. The field “rrname” keeps the domain name. Meanwhile, the statistical features are extracted from the structure of the DNS message in a specific packet window. Then, for each captured domain, we extract the lexical and third party features.
DNS statistical
Lexical features
Subdomain: Most malicious domains have few subdomains to mimic the real domain. For instance, to mimic www.facebook.com, the malicious domain could be in the format of www.facebook.f.com. In this case, the Top-Level Domain (TLD) is f and not facebook. However, people without enough background knowledge may be deceived.
Top-Level Domain (TLD): Based on the previous studies, most malicious domains are with specific TLDs for a long duration of time, such as .com, .pw, to name a few. The possibility of a URL being malicious is higher when its TLD historically has been used for phishing URLs.
Second-Level Domain (SLD): SLD is the most critical part of a domain. Extracting features from SLD can help us get more information regarding the organization that registered the domain name. For example, in www.facebook.com, facebook is the SLD.
Length: The length of the domain consists of SLD and subdomains. Because phishing URLs or malicious domains are lengthy based on the previously discovered malicious URLs, considering the length feature is necessary.
Numeric percentage: This feature indicates the percentage of numerical characters to the length of the domain.
Character distribution: This feature computes the distribution of each letter in the domain.
Entropy: This feature is based on the letter distribution and Shannon's entropy formula.
N-gram: This feature extracts the uni-gram, bi-gram, and tri-gram of the domain at the character level.
Longest meaningful word: This feature will find the longest word in the domain. To this end, we used a dictionary of words with their frequencies. Then, we apply dynamic programming to infer the location of spaces in the domain.
Distance from bad words: There is a blacklist of all suspicious and harmful words. After tokenizing the domain to meaningful words, we get the average of the Levenshtein distance of the domain's words from the blacklist.
Typosquatting method: There are generally five Typosquatting types including misspellings, singular versions, plural versions, hyphenations, and common domain extensions. We retrieve the list of 500 top domains from Alexa [15], which are all benign and known domain names. Then we extract the best matches from the dictionary to our domains, and each match has a score. Based on a threshold on the score, we mark the domain as a typo or not. For example, if our domain would be go0gle.com, it will return google.com as the best match with an 85% score; hence, we mark it as a typo.
Obfuscation method: To the best of our study, we considered nine different ways by which each domain can be obfuscated. If any of the following methods have been applied by the attacker, we mark the domain name as obfuscated:
1.existing @ in URL,
2.IP obfuscation Decimal 8 bits,
3.IP obfuscation Decimal 32 bits,
4.IP obfuscation Octal 8 bits,
5.IP obfuscation Octal 32 bits,
6.IP obfuscation Hexadecimal 8 bits,
7.IP obfuscation Hexadecimal 32 bits,
8.Detecting IDN: suspicious domain name may be encoded with Unicode or international domain names encoded with Punycode, and
9.Shortened URLs: to confirm if it has been shortened or not, we send a request to see if it gets redirected to the real URL or not.
Third party
Table 1: List of DNS-based features
Feature - Feature name - Description
Lexical:
F1 - Subdomain - Has sub-domain or not
F2- TLD- Top-level domain
F3- SLD- Second-level domain
F4- Len- Length of domain and subdomain
F5- Numeric percentage -Counts the number of digits in domain and subdomain
F6- Character distribution- Counts the number of each letter in the domain
F7- Entropy- Entropy of letter distribution
F8- 1-gram- 1-gram of the domain in letter level
F9- 2-gram- 2-gram of the domain in letter level
F10- 3-gram- 3-gram of the domain in letter level
F11- Longest word- Longest meaningful word in SLD
F12- Distance from bad words- Computes average distance from bad words
F13- Typos- Typosquatting
F14- Obfuscation- Max value for URL obfuscation
DNS statistical:
F15- Unique country- The number of distinct country names in window τ
F16- Unique ASN- The number of distinct ASN values in window τ
F17- Unique TTL- The number of distinct TTL values in window τ
F18- Unique IP -The number of distinct IP values in window τ
F19- Unique domain- The number of distinct domain values in window τ
F20- TTL mean -The average of TTL in window τ
F21- TTL variance- The variance of TTL in window τ
Third party:
F22- Domain name- Name of the domain
F23- Registrar- Registrar of the domain
F24- Registrant name- The name the domain has been registered
F25- Creation date time- The date and time the domain created
F26- Emails- The emails associated to a domain
F27- Domain age- The age of a domain
F28- Organization- What organization it is linked to
F29- State -The state the main branch is
F30- Country- The country the main branch is
F31- Name server count- The total number of name servers linked to the domain
F32- Alexa rank- The rank of the domain by Alexa
Proposed model
Figure 1: Stages of the proposed model
In the second stage, dataset generation, we send HTTP requests using a Python script to the collected domains and the related network packets are captured using Wireshark. The detailed steps are illustrated in Figure 2. First, all the domains are retrieved from the client's local database (steps 1 and 2). Then, an HTTP request is sent to each domain's web server through the Internet and the OK (200) response is received back in steps 3 and 4. Meanwhile, the DNS packets are dumped and the domains with a timed-out request are just ignored. To avoid long waiting times, we set the timeout parameter to two seconds.
Figure 2: DNS packet capture
The categorical features namely, sld, emails, domain name, country, registrar, state, registrant name, longest word, organization, tld are transformed and represented as continuous values. Average of n-gram frequencies, char distribution, typos, distance from bad words were computed. Also, creation date time and domain age are converted to seconds and years, respectively. The rest of the numerical features remain unchanged. Besides, we calculate the maximum value of the nine obfuscation methods and merge them all into one feature of obfuscation. Finally, we create a CSV file of all the post-processed features values.
The third stage trains the ML model, and the fourth stage validates and evaluates the model using fold cross-validation.
Dataset
We managed to collect more than one million domains from various sources falling under four different categories of malware, spam, phishing, and benign domains. All the domains have been collected between May 2019 to June 2019 and later updated with domains from December 2020 for further validation. Each domain category is briefly explained as follows:
Malware domains:
Malware category refers to the domains that have been previously identified to generate any general type of malware including drive-by download, DGA-based botnets, Distributed Denial of Service (DDoS) attacks, and spyware. The malware domains were collected from DNS-BH and malwaredomainlist.
Spam domains:
Spammers employ different ways to find valid email addresses for sending bulk emails. Dictionary harvest attack is one of the common ways to seek a valid email address by randomly sending mail to widely used mailbox names for a domain, such as info@example.com, admin@example.com, and support@example.com. We have obtained Spam domains from jwspamspy [21] which works as an e-mail spam filter for Microsoft Windows.
Phishing domains:
Phishing domains imitate the looks of legitimate websites and leverage social engineering techniques to trick users into clicking the malicious link. Upon clicking the fake link through email or SMS, the user is directed to an imposter website asking for the user's login credentials and private information. In our dataset, the phishing domains were collected from OpenPhish and PhishTank which are collaborative phishing verification websites where the users submit the phishing data, and the community users vote for it.
Benign domains:
All the domains that are not in the above categories are deemed to be benign. We gathered all benign domains from Majestic Million.
Table 2 shows the breakdown of the dataset in terms of the number of collected domains (#original domain) in each category of malware, spam, phishing, and benign. After sending HTTP requests to each domain, some of the domains do not respond, e.g., C&C servers that are not alive anymore. The remaining domains that respond OK (200) are logged and, associated DNS packets are dumped. In Table 2, the domains and packets that have been successfully processed are identified with columns “#domains processed” and “#packets processed”, respectively.
Table 2: Statistics of the domains dataset
Category -Original domains -Domains processed -Packets processed
Malware -26,895 -9,432 -182,266
Spam- 8,254 -1,976 -61,046
Phishing -16,307 -12,586- 95,492
Benign- 988,667- 500,000 -6,907,719
Analysis
License
- Samaneh Mahdavifar, Nasim Maleki, Arash Habibi Lashkari, Matt Broda, Amir H. Razavi, “Classifying Malicious Domains using DNS Traffic Analysis”, The 19th IEEE International Conference on Dependable, Autonomic, and Secure Computing (DASC), Oct. 25-28, 2021, Calgary, Canada
You can download this dataset from here.

Researchers named among top researchers for Canada 150

The cybersecurity Research and Academic Leadership award, Canada 2019

The cybersecurity academic award, Canada 2017